NCBI简单的来说就是一个生物信息库,四面八方不分国界地吸收着关于生物的一切信息,是一个洋溢着生命气息的软件。
它是富有的,用中国话说就是包罗万象,不可胜言,车载斗量,斗量筲计,浩如烟海,换句话说就是“贫穷限制了我们的想象”。有多富有就会有多强大,有多强大也就有多好用,好用而又免费那就是天上掉馅饼,喜欢什么馅就接什么馅喽。
下面就先介绍两种馅,吃对了,吃饱了就可以扩展科学新领域啦。
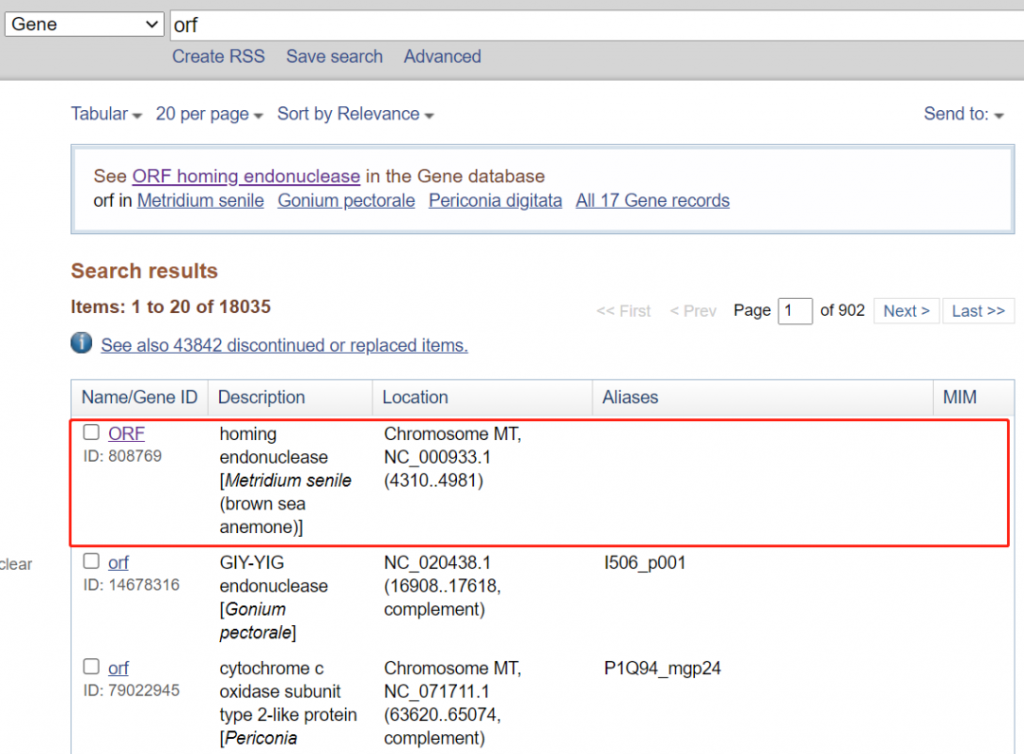
当我们知道一个基因的名字,但是并不清楚这个基因的具体信息时,就可以通过名字对其进行检索,在NCBI的首页在检索的下拉菜单中选择Gene,输入基因名字,点击search,关于这个基因的信息就无处躲藏。
举个简单的例子,比如这几年一直困扰我们的冠状病毒的一个基因orf,检索后就会出现下图的信息。
点击红框部分就可以出现这个基因的信息,然后我们就可以看到下图的信息,只要点击每个向下的箭头就可以展开详细的信息。
这还没有结束,在展开的具体内容上,鼠标就会变成小手手,点哪都会出现相应的具体信息,手手动起来还怕看不穿它的前世今生吗?
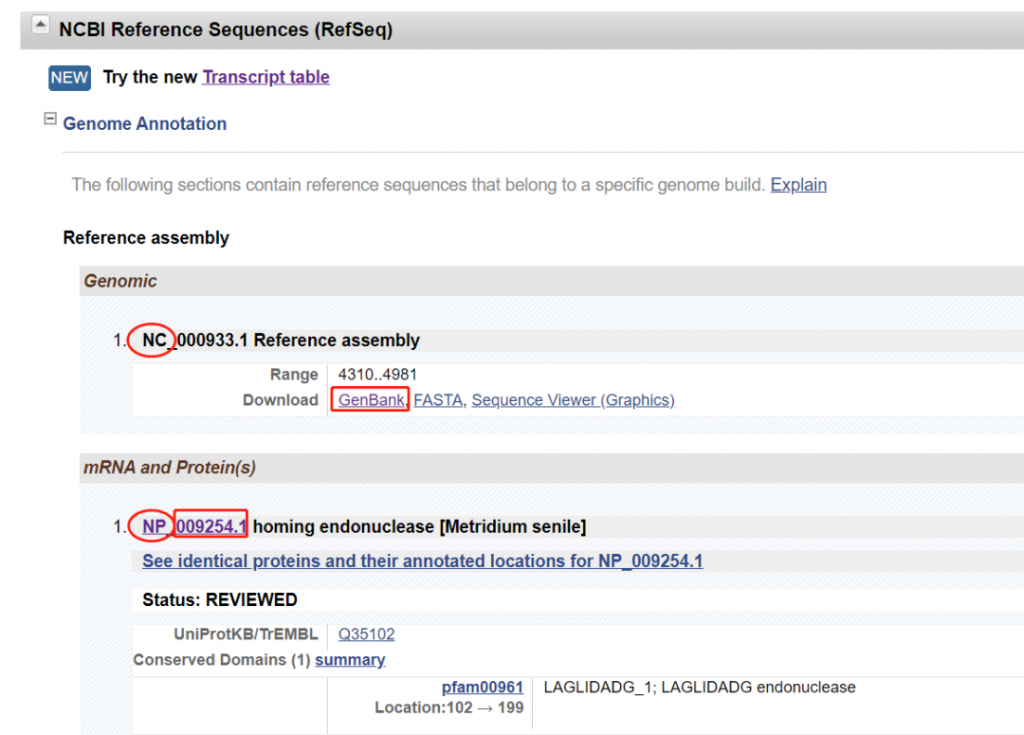
不论是基因还是蛋白最需要关注的就是序列部分,序列就是在NCBI Reference Sequences(RefSeq)条目下进行查看。
如下图,圈红的NC是基因,NP蛋白。点击框红部分,将显示的页面翻到最后就可以看到具体的序列信息了。
以蛋白为例,检索到的蛋白序列如下图。

拿到基因的ID就是拿到了确认它唯一身份的证件,这个要比名字更容易锁定,毕竟基因名称也像人名一样,重名的太多了。
检索方式是与上述名字检索相同的,只是输入的是ID的序号。剩下的又是上述的前世今生的信息了。
在科研中最大的成就便是“新”,新领域、新事物、新功能哪一个不是让人瞠目结舌的大惊喜,这就是科研界的打拼新天下,扩充新疆土。
在这片疆土中序列就是一个标志性的存在,序列中所谓的“新”就是排除“旧的”,这就体现了数据库的重要性。
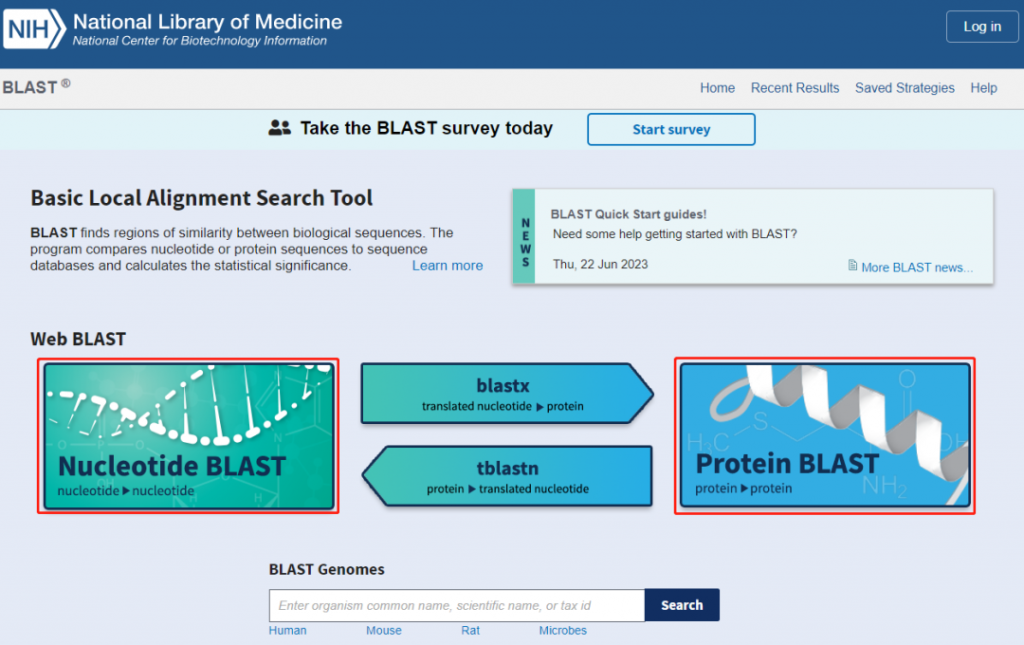
回归NCBI首页右侧Popular Resources下的BLAST出现下图,左侧红框是核酸序列的比对,右侧红框是蛋白序列的比对,根据需要自行进入。
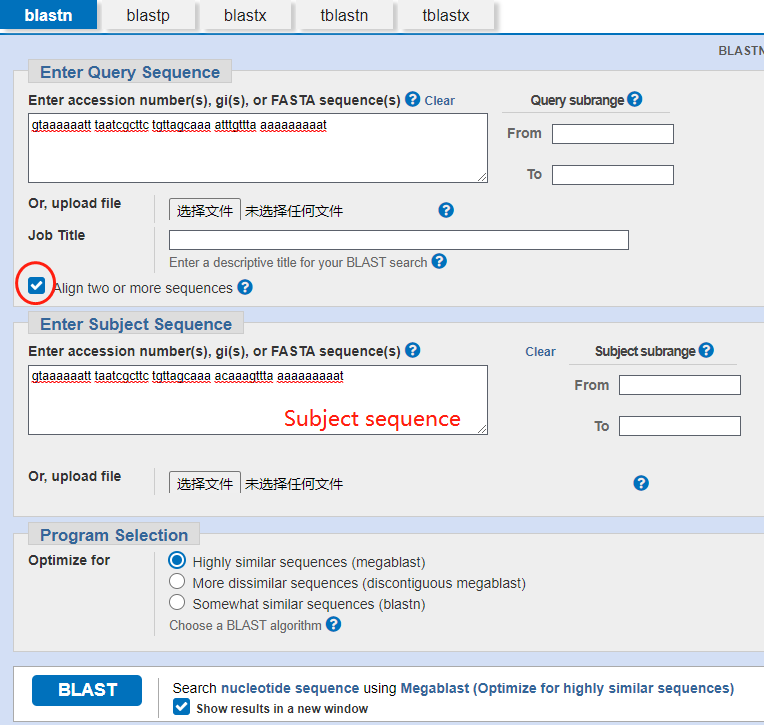
下面以核酸序列比对为例,输入需要检索的序列(Query Sequence),在右侧还可以对检索的序列进行区域的设置。
或者是直接上传本地文件,如数据库登录号、NCBI gi号或FASTA格式的序列的列表。
图中绿框部分是对检索范围的一些具体的设置,黄框是对检索结果进行优化,可根据具体情况自行设置。
检索时可以将圈红部分选中,这样检索结果就会在新的窗口展示,点击BLAST,在等待新窗口时,还可以在先前的窗口对另外的序列设置检索信息并进行检索,互不冲突,节省时间。
以一段序列为例,进行展示,检索结果如下图,分为3个模块:基本信息、以图形展示的检索信息、具体的检索结果信息、相似序列的分类信息。
基本信息中需要分析的几个参数,scientific name(系列所在的物种)、query cover(检索的序列与库中的序列覆盖度)、E值(两个序列对比的可信度)、per.ident(两个序列的一致程度),当query cover和per.ident均为100%时可认定为相同的序列。
在答复中,经常需要将本申请的的序列与对比文件进行比对,那么这种对比通过NCBI又是如何实现的呢?
在检索信息页面,将圈红的选中,就会再出现一个填写序列的对话框,将需要对比的序列填入,点击BLAST。
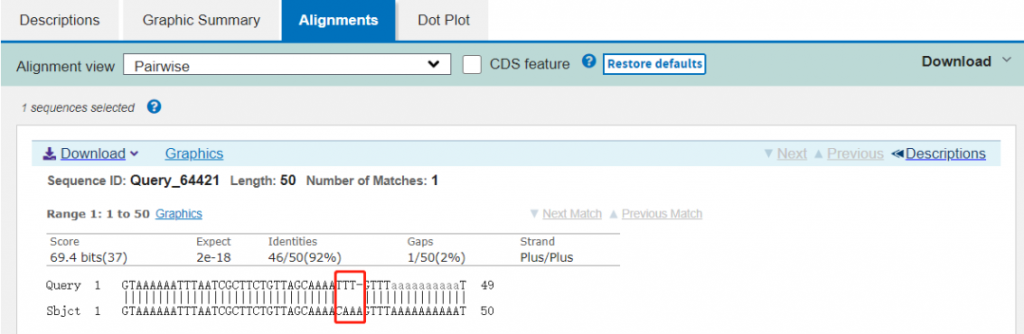
检索结果如下图,相似的是92%,序列的差别就是红框部分。
好啦,小编就先分享到这了,希望这些能帮助到大家打天下。


















暂无评论内容